Getting Started With Automated Image Builds in Azure

Automating DaaS and AVD Images in Azure
- Intro
- Common Existing Process Scenario
- The Tooling to Automate the Process?
- What Other Options?
- What is Suited to “Always Latest”” and What is Not?
- Flow Process
- Gotchas
- Documentation and Wiki
- Citrix Cloud DaaS Updates
- Wrapping it up
Intro
Anyone in our industry has at some point heard/been subject to the discussions of automating image builds for Citrix, VMware, AVD or any other virtual desktop solution in the market. It is not a new concept and has taken many flavors over the years, ranging from ConfigMgr deployments on-premises, to MDT frameworks provided by XenApp Blog and others, out to more agile modern build approaches such as Packer, Ansible and anything in between.
Automation can be a daunting concept, particularly for those that are not naturally “developer minded” like myself. I love scripting and automation, but I find it a challenge, and am amazed at some of the brains that can fly around different toolsets and develop capabilities on the fly. But automation doesn’t need to be a frightening concept and can take many forms, from basic to advanced. If we think about the why of automation when it comes to image builds, the tools become a secondary consideration and factor. My why is simply this:
Images support users. Users are important. Consistency is king, installing things is boring, and I am not always going to be the one that builds these images
To that end, I will suggest that anyone who executes anything in their images in a repeatable fashion, is already somewhere along the automation journey. Be it batch scripts, package deployents via PDQ Deply or MDT, copy and paste command line installs into PowerShell, or a one-liner chocolatey package, all of these are supporting consistency, repeatability, a complete disinterest in clicking buttons and laying an easily understood execution for the next person who steps in.
There are some key undisputable values of investing in some image automation methodologies:
- Consistency. The image build process is the same every time. Code is Code. Execution of code and associated configurations is the same every time. This results in
human error reductionand guaranteed repeatablity. - Flexibility. Building on the the consistency logic, there is flexibility of building the same thing, consistently, on multiple platftorms. With some tools, it is relatively simple to deploy the exact same base, across many different infrastructure providers. It blows my mind that by simply changing 8 or 9 attributes in a packer build script, we can effectively (within reason of course) build an identical image on a different cloud platform or hypervisor.
- Image debt is no joke. I have worked in many environments where there is a fear of upgrades or rebuilds because knowledge of what is in that image, and how it got there, is gone. This typically means projects bigger than Ben Hur when it comes time to start refreshing Operating Systems or hypervisor platforms (yes yes, we can convert, but that’s just compounding the problem). The opposite of image debt is
Future Proofing. Automation supports future proofing. - Version Control. This is a simple develpment concept, but if you have your build process in code, you can see exactly what changes. This is far less prone to error than asking the person next to you what they installed whilst having a beer on a thursday night and patching an image…
- Think of who comes next. As a consultant, I saw plenty examples of castle building. One message I always wanted to impart on consultants and customers is
Think about who comes next. There is nothing worse than logic or history being trapped inside someones head. Everything we touch an do should be actioned in a way that is logical and easy to pick up for the next person that comes in. Putting processes into code (in whatever fashion that is) sets up everyone, now, and in the future for success.
This post is not one to bant on about you being wrong for not automating builds (you aren’t bad for not doing it), it is aimed to show some simple concepts (and some more advanced ones) learned on my journey across customers and builds. Maybe you will take some learnings, maybe you will think it’s rubbish - either way is fine.
A note to Aaron Parker, the man is awesome and all over this stuff. It was a pleasure to work with him over the years and see these ideas and concepts come to life. My brain is in constant awe of not just his ability to see a clear line through problems/challenges, but his willingness to explain and address them with grace and patience. He also has delightful hair. Just saying…
Before we dive in, here is a key takeaway that I think is important:
Each environment is different. Not every application is suited to always being the latest, and judgement should be applied accordingly. Just because you can pull down something from it’s source, doesn’t always mean you should.
One of the single biggest challenges with an always-latest methodology is that it is really unknown on what breaks what, and what works with who. One problematic application can result in a completely dead image, and with the automated latest approach frameworks noted below, outside of hosting the packages yourselves, there is no way to handle a specific version of an app. So be warned, and consider carefully.
Common Existing Process Scenario
I am building this post around a scenario I saw reguarly and I am sure resounds with some. However, the concepts are the same across almost any platform.
Build Platform: Azure Desktop Delivery Platforms: Citrix DaaS & Microsoft AVD Use Case: Virtual Desktops Initial Build Process:
- Pull image from Azure Gallery
- Run Windows Update
- Install Applications
- Make changes to applications
- Seal Image
- Release to test
Image Update Process:
- Open Master Image
- Make changes
- Seal image
- Release
Frequency: Monthly at the worst - often fortnightly given the security landscape
This process is fine. In fact it’s great. But it is quite time consuming and if something fundamental needed to change (like an Operating System change) the whole process has to be taken care of again. And again. And again. Every month there is human interaction and configuration items that may just slide on in there and be lost forever more.
The Tooling to Automate the Process?
The above scenario is perfectly suited to an automated image build process, here is the tooling and some considerations around how I tackle it.
- Azure DevOps: Azure Devops (ADO) sounds far more frightening than it is. It is basically, in the context of what I want, an Orchestrator, a code repository and a documentation wiki. The solution is a PaaS service straight out of Azure. Depending on how complex your requirements are (and how long it takes to execute), you can get away with the free option. Within DevOps, I decided to avoid the “build gui thingo” and stuck with YAML based pipelines, I found these were the most flexible and allowed me to port them across customer environments with no fuss, along with having version control alongside everything else.
- Azure Keyvaults: Keyvaults are not a hard and fast. I use them in the context of image builds to store secrets. Usernames, passwords, keys etc. DevOps can integrate with Keyvaults very easily and pull them into pipelines on the fly. Conversely, DevOps has it’s own equivalent concept in the form of library variable groups. These achieve the same result, however don’t offer as much flexibility as Keyvaults IMHO.
- Packer: Packer is awesome, it’s job is to do the actual image build. So in the context of this scenario, Packer (which is natively supported on Azure DevOps runners) is responsible for provisioning a machine in Azure (or anywhere else), and then executing a whole load of things you ask it do. Patching, Image changes, execution of scripts, the list goes on. When Packer is done, you are typically left with an image you can use for
something else. What gets left depends on the platform - sometimes it’s a VM, sometimes its an image, sometimes its a snapshot. - PowerShell: Everything I do tends to be wrapped around PowerShell. Image builds and application deployments are no different. I take everything I do within the image build process and put it into a PowerShell script or multiple scripts. Packer executes those scripts for me. The reason I like this, is that done right, those same scripts can be taken to any tool that can execute them, they are self managed little bundles of goodness.
- Chocolatey: Chocolatey offers a pretty cool way of retreiving and deploying packages from a public repository. There is a whole world of chocolately including hosting your own repositories. In the context of this scenario, it’s job is to simply pull down the latest version of applications and deploy them from the public repository. Chocolatey is nice,
until it's not. You are at the mercy of the wonderful humans (and bots) that manage those packages. I have been bitten multiple times with changes to architecture (x86 to x64) etc that just magically turn up. Sometimes the latest version of the app isn’t there and sometimes, downloads just fail. But, on a whole, it is a great tool in the toolkit. I user PowerShell to execute chocolatey application installs - one app per script. - Evergreen: Evergreen is Aaron Parkers love child (one of them). It is very different from Chocolatey in the sense that it’s job is to look at vendor provided download lists, and tell you
whatandwherethe latest version of that application is. From there, you are responsible for downloading it and installing it the way you want it. The good thing about this approach, is that if the vendors are playing nicely, there is typically a nice structured and up to date source of truth. I have moved many packages from Chocolatey packages across to Evergreen, or used Evergreen when there is no Choco package. I wrap things into a one-app-per-script logic for Evergreen Apps. - Nevergreen: Nevergreen is the spinoff from Evergreen by Dan Gough, and follows the exact same logic but with a different method. Whilst Evergreen looks at the download links from the non-problematic vendors, Nevergreen fills the gaps by web scraping to attain download links. The product is awesome, and covers many packages that Evergreen cannot pull. Like Evergreen, I wrap things into a one-app-per-script logic for Nevergreen Apps.
- PSAppDeploymentToolkit: All this talk about chocolate and green/not green stuff is great, but there is a whole world of applications that are not publically accessible, are not suited to being “latest release”, may be in house developed, or may be complex and need to be controlled. The Powershell Application Deployment Toolkit is a god send for these applications, and allows you to use a highly customisable and simple pre-defined framework to install pretty much anything you can think of. This is what I use as a standard for any application that is not a
latest versionapproach app. It’s easy, well documented, well understood, scalable and supportable. Tick. Once I have the packages, I use (wait for it) PowerShell to execute the deployment in a one-app-per-script logic. For a handy tip, check out the Master Packager Master Wrapper product - this thing is amazing for introducing simplicity into the PSADT. - Storage To install application packages, you need to have somewhere to store them. Often with packer builds, you will be be deploying an image that is disconnected from any network, and uses an isolated approach. As such, you need somewhere that can be reached in a secure fashion from anywhere with an internet connection. Azure Storage Accounts with Blob Storage tick these boxes, You can store the relevant access credentials (Keys and URLS) in your keyvault of choice, and pull them in to your pipelines. PowerShell scripts can then use the credentials on the fly to download and execute those packages. Simples.
- Pester: There is no point building an image and hoping for the best. Pester is a great framework for testing that everything you want to be there, is there. For each app we deploy, we want to test it’s there, or associated configurations are there. Pester is ideal and even offers a nice results export which integrates with DevOps for reporting. Win.
What Other Options?
There are many flavors of tooling that can help with all levels of automation. What I chose may work for some, but there are plenty of other tools out there with all sorts of capability, a short list below just to identify some of the options and scope of capability:
- Ansible. The more I play in this space, the more I see Ansible as amazing. One of my favorite things here is the ability to automate pretty much anything on any platform. You may choose to build an image with tool X, Y or Z and then have Ansible lay the configurations over the top. Ansible is so stupidly powerful and a pleasure to work with that I am now leaning towards this as a default for all automation jobs including ongoing maintenance jobs etc.
- Azure Image Builder. AIB uses packer under the hood, but runs nativly within Azure as a Service. Whilst it’s nice and all, I couldn’t find a reason to go down this path when Packer natively offers so much flexiblility - but hey, each to their own.
- PDQ Deploy. I spoke a fair amount about end-to-end building and automation, but if you have existing images and build processes to create those images, then PDQ is a sensational tool to overlay applications and update logic. Cheap and easy, the tool offers a nice middle ground for those not commited to ground up image builds every month.
- MDT I mean, it’s kind of hard to ignore MDT given its simplicity and what it can be extended out too…for deployments not based on IaaS, MDT may stil be an awesome tool to lay down the Operating system and then applications over the top. It can be combined with other tooling or handle all the required tasks itself, it’s just somewhat limited in scope when we think about multi-cloud environments.
What is Suited to “Always Latest”” and What is Not?
There are a range of considerations which apply to applications which make them candidates for an always latest methodology:
- Is the application actually
availablefor an easy download? - Is the application version
specific to your environment? - Do
other applicationsin your environment require a specific version forintegration? - Is the application critical, and have
current releasesproven problematic? Whatare your images doing andwhat purposeare they serving?
Here are some experience based opinions on what is suited to an always latest approach (and what may not) in a common image build:
| Application | Latest | Justification |
|---|---|---|
| Citrix components | No | Citrix won’t make their software available publically. They make the hell no list, even with previous workarounds. There is also a release quality consideration with current releases |
| FSLogix Apps | No | FSLogix release quality has been crap since Microsoft took over. Even though there are choco packages and evergreen methods of pulling this software, I would suggest this is version controlled and joins the hell no list |
| Chrome, Edge, FireFox browsers | Yes | Given the amount of security holes and patches that are released, these guys land in the yes bucket for me. This could be a contentious point of course |
| Microsoft Teams | Yes | Teams is errrrm. horrible. Hopefully each version fixes crud from the prior, and we need the features that tend to come with each release for those poor people that have to consume it |
| Adobe products | Yes | Surely nothing is tied to version specifics here |
| Utility Apps | Yes | Greenshot, 7zip, BIS-F, VLC etc - all prime candidates to run the latest and greatest |
| Microsoft 365 Apps | Yes | This is based on the assumption that monthly patching also means updates to Office. If that is the case (and it should be) then Microsoft 365 apps makes the cut via Evergreen |
| Microsoft Office | No but Yes but No | Good luck with that. You are going to be storing that install media and packaging accordingly |
Flow Process
Ultimately, we end up with a basic flow process that works as below:
- Azure DevOps executes the pipeline on a schedule
- Some basic variables are set or manipulated to handle the output of snapshot naming conventions
- Packer creates it’s Azure Resources and starts building the Image including:
- Windows deployment
- Windows patching
- Application deployment
- Choco Packages
- Evergreen Packages
- Nevergreen Packages
- PSADT packages (everything lands in PSADT packages as per above - stored in an Azure Storage Account)
- Windows patching again
- Image Optimizations
- Image customisations (Start menu, default user profile etc)
- Deletes all temporary install files
- Image Sealing (BIS-F using shared configuration)
- Pester tests the image and outputs an XML config for use with DevOps job status
- Packer dumps out a snapshot into Azure which is ready for MCS consumption
- Packer dumps out an Azure Image (which is useless for Citrix), so DevOps executes a az cli command to delete it
- Packer cleans up after itself, removing all temporary resources
- DevOps executes a PowerShell snippet which updates a Machine Catalog in Citrix Cloud with the latest built image for testing
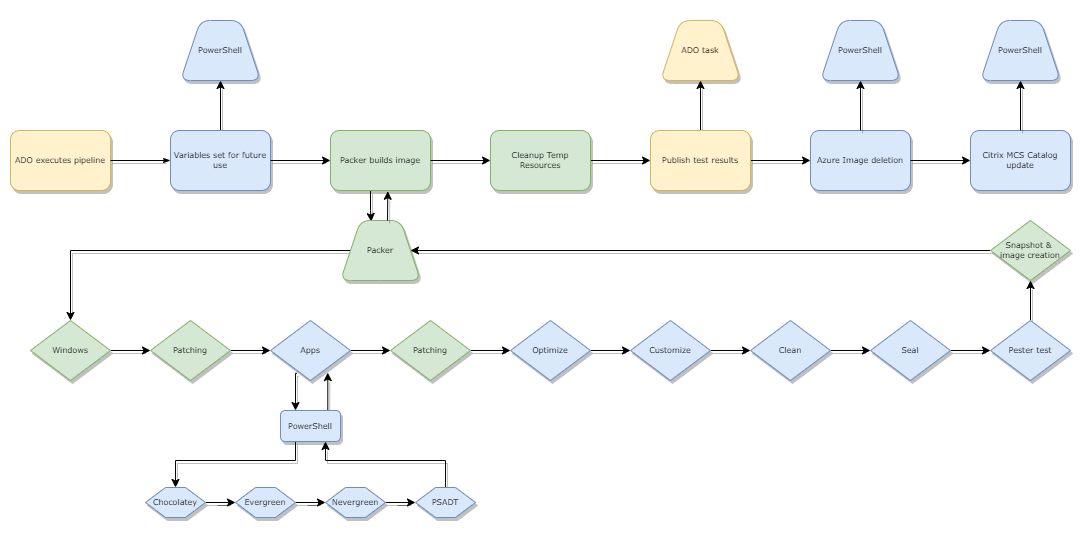
For the AVD side of things, I simply copied the pipeline (it’s YAML after all), and then altered the build jobs for what I did and didn’t want. 80% is the same, but I don’t care about snapshots and actually want to keep the Azure Image. I also don’t care about Citrix components in the AVD builds, so removed them.
I wrote a piece a long time ago about the User Environment and what goes where. I live by that logic today, and it aligns perfectly to this build process methodology. Configuration gets delivered post build by configuration tools, image build processes are simple and non complex.
For one deployment where we implemented this logic, the customer (wonderful folks) were already using DevOps pipelines for other processes with their LOB apps. They were able to implement (very very simply) an extension to their app build processes that pushed custom content into the appropriate storage account, which our image build then pulled down. This meant no double handling from anyone - the Apps team responsible for compiling and releasing code updates, could push their code knowing that Citrix and AVD images would pull that code, and the team responsible for the EUC images were zero touch.
Gotchas
Here be some learnings and things to watch for:
- Naming convention for snapshots vs Images This was a bit of fun initially. I wanted outputs (snaps and images) to be named based on a
date and build runlogic so that if I built multiple images on the same day, I would have a differentiator. That’s easy enough using variables, but our friends at Microsoft have different naming rules for Images vs Snapshots, so that wasn’t playing nicely. But hey, this is pipeline work, so I simply added a task to take the build variable, manipulate it via PowerShell (Surprise!) into a format that works for both, and then pass that out to the next job (Packer). - Paid vs Free Tier (Runners). It doesn’t take long for build jobs to start taking a bit of time. The challenge with DevOps on a free tier is that your jobs have a contiguous runtime limit of 60 mins. Once that 60 mins is up, the job terminates, without any form of nice logging I might add. You may need to consider paid plans for DevOps if your jobs run longer than 60 mins.
- Workarounds for labs (hosted runners with Azure DevOps Orchestration). Backing onto the above topic, I am tight and didn’t want to pay for long running jobs in my lab environment, so I decided to use a Hybrid Runner (basically a server that you own and manage to execute the actual jobs). I spec’d this guy small, and fell back on pipeline methodology to 1) power on the VM when I wanted to run the job and then 2) power off the runner once the job was done. This was achieved through a simple AZ CLI job. There is much more flexibility with Hybrid (self-hosted) runners in lab environments.
- App deployment failures can result in pipeline failure If an app deployment fails and comes back with anything other than a successfull error code, the entire job can fail in DevOps. This is a bit of a pain in the butt, so I used a logic to override failures with a specific exit code. To make this flexible, I used a variable in DevOps (OverrideExitCode) and set this to whatever was required. Then in my deployment scripts, I simply reference that Env Variable to override any form of fail. This helps to manage non-critical components that shouldn’t halt the pipeline. Just food for thought and only used for testing.
- Chocolatey Fails. I got bitten a few times with Chocolately packages refusing to play nicely. As soon as I was bitten, I pivoted to something else. Evergreen where I could, and then over to PSADT if required. At least with PSADT I was always in control.
- Citrix. With Citrix introducing MFA requirements to download basic software components. Along with some questionable releases, the risk of latest and greatest was simply too high and too hard, so back to PSADT for these components.
- Long live environment variables. Something I am putting here as a note is the importance of understanding environment variables and how they flow. Chances are, once you learn and understand this process, you can move to almost any automation platform and start learning quickly. Env variables were my biggest stumbling block - once I understood them and how they flow, it was game time (I am thick…)
- YAML and HCL and JSON are fickle beasts. One step wrong and it’s all over - watch your syntax and use vscode to help you understand how to write.
Documentation and Wiki
Azure DevOps offers an inbuilt, easy to use Wiki. I decided to use this for documentation and capturing processes for customer deployments. It left them with an easy to consume set of documentation that wasn’t tied to Microsoft word and lost in the pile of “everything else”. The wiki uses Markdown, so it is easy as pie to understand and update, and meant anyone in charge of pipeline alterations had no excuse to not update it and leave things out of date.
Citrix Cloud DaaS Updates
Martin Therkelsen wrote a very cool guide on how to leverage the Citrix Cloud DaaS APIs to automate image releases. This was something that opened up all sorts of fun and really brought value to automation engagements. To be able to not only build the image, but have it ready for testing all zero touch was pretty cool. Having a UAT/Test Catalog in Citrix DaaS was part of the process. We left production release flows out of the process for obvious reasons. But it is effectively the exact same flow.
Watch out when using the secure key from Citrix if you are a consultant. The key logs all DaaS events as the person who generated the key, not the key itself. So every time a Catalog is updated at 3 in the morning, it will appear as whoever generated the key is in there doing things.
Wrapping it up
This post is aimed to help with automation concepts and some thought provoking concepts. I have purposely refrained from posting “how to” guides because there are so many awesome examples out there already, and each environment will use a slightly different approach. I am happy to provide snippets or examples of anything should there be a need or interest - reach out if needed.
Importantly, I want to highlight some giants in the industry who have laid some awesome ground work for all of this stuff. In no specific order:
Enjoy the world of automation, it is far more rewarding thing clicking buttons over, and over and over again, and if my brain can get there, anyones can.
