Azure Site Recovery and MCS Provisioned Workloads

Getting down and dirty with Azure Site Recovery and Citrix MCS provisioned workloads
- Intro
- Citrix and Azure Site Recovery Considerations
- Citrix and Azure Site Recovery Failover
- Scenario Outlines
- Summary
Intro
Azure Site Recovery (ASR) is Microsoft’s multi-faceted solution for performing services such as Disaster Recovery (DR), Business Continuity Planning (BCP) execution and migration services (these days primarily wrapped into the Azure Migrate service).
When deploying dedicated/persistent machines on the Microsoft Azure platform, it is often desirable to protect these workloads via ASR, providing cross-region failover capability. Chances are if you are a Citrix customer, you may be deploying both pooled and dedicated workloads via Citrix Machine Creation Services (MCS), which does not lend itself well to ASR capabilities, or several other Azure availability technologies (yet).
This post focuses on dedicated/persistent workloads deployed via MCS on Microsoft Azure. If you are deploying pooled workloads, ignore this article and simply deploy a secondary pooled catalog in your target (failover) region, ASR serves little to no purpose for you outside of maybe replicating your master image across regions.
Citrix and Azure Site Recovery Considerations
My fellow CTP and all-round good fellow Neil Spellings and I discovered several considerations when dealing with ASR and Citrix workloads when consuming Citrix Cloud:
- Azure Subscription architecture. This is often complex at scale due to Azure limits
- Azure Hosting connection architecture (often directly related to your subscription architecture)
- Citrix Resource Locations/Zone architecture
- Citrix Cloud Connect placement and registration configuration for VDA workloads
It is worth having a read through the Citrix Virtual Apps and Desktops Service on Azure tech zone article to wrap your head around considerations.
The long and short of MCS deployed workloads, is that you simply cannot successfully leverage ASR to protect VM’s and have them failed over to another region whilst keeping Citrix power management awareness in check. This is down to the fact that with MCS deployed workloads, the HostedMachineID and HypervisorConnectionUid attributes cannot be altered, which is what Citrix uses to identify the workload from a power management perspective. In Azure, this is identified by the Resource Group (in lower case I might add) that the machine resides in and the HypervisorConnectionUid. So whilst we can replicate the workload, and have it restored, we end up in a split-brain scenario where power management awareness proves immensely problematic (ASR also does not replicate the storage account which MCS uses to cache power management status etc. from Azure) and brokering does not occur appropriately.
MCS dedicated workloads are a “deploy once and leave alone” methodology from Citrix and as such, keeping the machines in an MCS catalog serves little to no purpose once deployed outside of some optimized power management calls to Azure. Given that MCS blocks our ability to leverage ASR appropriately, our first step is to boot MCS out of the way (thanks for the assist!) and leverage a “manual power managed” Catalog and Delivery Group. You may wish to continue to consume MCS provisioning to deploy the workloads from a central image, but post provisioning, it will be beneficial to move these workloads away from MCS management, and unlock some additional controls and capability that ASR offers.
You should ensure that if you leverage MCS to deploy your persistent VM’s, that you power on these machines at least once post provisioning. MCS leverages “on-demand” provisioning in Azure, so the VM does not actually exist until the first power on occurs (hence why dedicated workloads still use an identity disk on the first pass).
I have written a script here that actions the following:
- Grabs all machines from an MCS dedicated Catalog
- Loops through each machine and removes it from the existing Delivery Group if assigned
- Removes the machine from the existing MCS Catalog but leaves the machine account in Active Directory
- Removes the ProvVM details, but retains the actual VM
- Resets the OU attribute on the ProvScheme in case the VM targeted is the last in the catalog – I found a situation where this attribute was cleared after the last machine was removed – this may be resolved in the future and the value appears to be ignored on the second pass of provisioning anyhow
- Adds the machine to a manual Catalog (Power Managed) I assume the Catalog already exists (if it doesn’t the script bails)
- Sets the Machine
HostedMachineIDandHypervisorConnectionUiddetail based on the original values (these are available for alteration on a Manual Catalog) - Adds the machine to a manual Delivery Group (conversely, you can bypass the rules of Citrix Studio with PowerShell, but we won’t go there for now)
- Mirrors the existing assignments associated with the VM
- Optionally changes the published machine name to either the VM name or value you specify
What it does not do:
- Create any Catalogs
- Create any Delivery Groups
- Alter any Delivery Group attributes including access assignments – make sure these are correct else you will not have access to your restored VM’s
- Clean up any MCS remnants such as identity disks (yep they exist for dedicated too though are only used for first provisioning)
Once you have performed this migration, we unlock the ability to leverage Azure Site Recovery to protect these VM’s. There are still several considerations when dealing with failover scenarios, but I have a second script to cover this (read on).
Conversely, this script should also do the job with traditional on-premises deployments where you need to change hosting connection details such as a new VMware VCenter – but you would have to ensure you are running on a Delivery Controller and I haven’t tested it (no reason for it not to work).
Citrix and Azure Site Recovery Failover
Once you have a manual catalog and are protecting your dedicated workloads with ASR, you will need to think about the following:
- Leverage registration groups and disable controller auto-update via Citrix Policy
- Identify your source (production) and target (failover) zones (resource locations) as you will need to re-zone your Catalogs in a full failover scenario
- Identify your source (production) and target (failover) hosting connections. If these are different, then you will need to update each VM on a failover scenario to ensure that the hosting connection is updated appropriately
- Identify the target (failover) Resource Group in Azure for the protected workloads. This will need to be updated on failover so that Citrix is aware of where the machine now lives and can manage it accordingly
- Identify the source (production) Resource Group of the machine as we will need to update this value on a failback
I have a second script here which will perform the following:
- Grabs all the machines in the source (production) Catalog – I assume in an ASR failover, that you have lost the entire region and as such all machines in the Catalog – this logic may need enhancing in the future, but for now, it should suffice
- Updates the
HypervisorConnectionUidif different than the original - Updates the
HostedMachineIDwith the target (failover) Resource Group (in lower case!) - Changes the Zone of the source (production) Catalog to that of the restored VM. Without this change, the connections are never established regardless of the registration state
- Prompts for you to manually set the source (production) hosting connection into maintenance mode IF the hosting connection is different (rare). There is no hosting alteration available via the Citrix Cloud PowerShell SDK, so this is not something that could be actioned in code. This only applies if you have a different hosting connection for your failover region
My suggestion is to leverage the JSON input capability, as it will allow you to map out both your failover and failback scenarios in a controlled fashion.
With the above in place and executed, the following is entirely possible:
- Protect dedicated VDI workloads cross-region with Microsoft Azure Site Recovery
- Lose an entire source (production) region and register appropriately with secondary Cloud Connectors in the failover region with no policy changes
- Provide full power management for the failed over machine for the duration of its lifecycle in DR
- Provide full failback capability once the source (production) region is restored
Scenario Outlines
I took into consideration several scenarios whilst performing my testing, outlined below. There may be others, but these are the low hanging easy to test and document for now.
The following components are common across all models:
- Azure South East Asia is primary, Azure East Asia is secondary
- Recovery Services Vaults exist in the Azure East Asia Region
- Both Regions have their own Cloud Connectors and are treated as a Resource Location in Citrix Cloud
- Group Policy uses Registration Groups to ensure that Cloud Connectors in Azure East Asia are only used when Connectors in Azure South East Asia are not available
- The hosting connection object is located in the Azure South East Asia Resource Location (Zone)
- The source (production) catalog is housed in the Azure South East Asia Resource Location
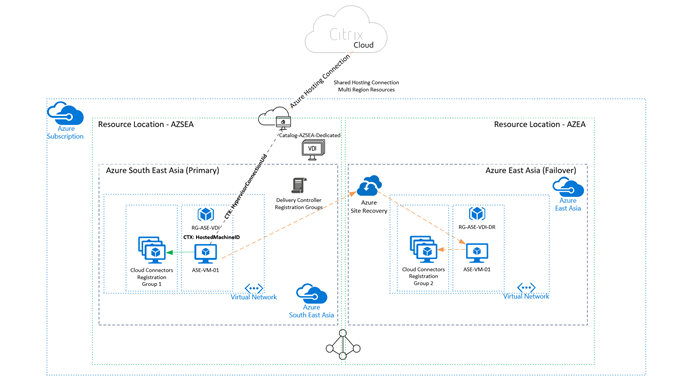
Single Azure Subscription, single hosting connection, multiple Azure Regions
Here is the subscription outline in a happy state:
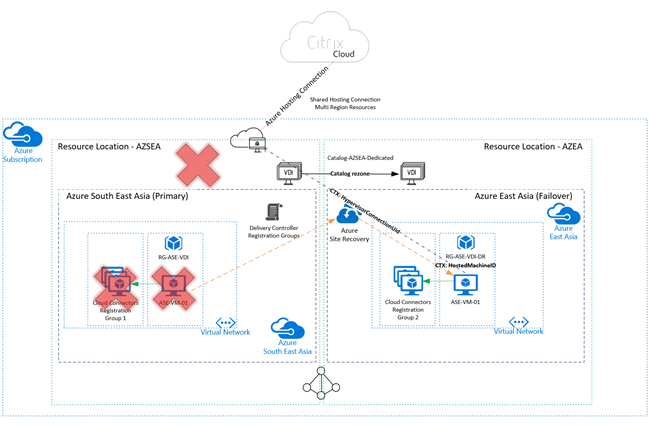
And here is what happens in a failure scenario, where we effectively lose the Azure South East Asia region:
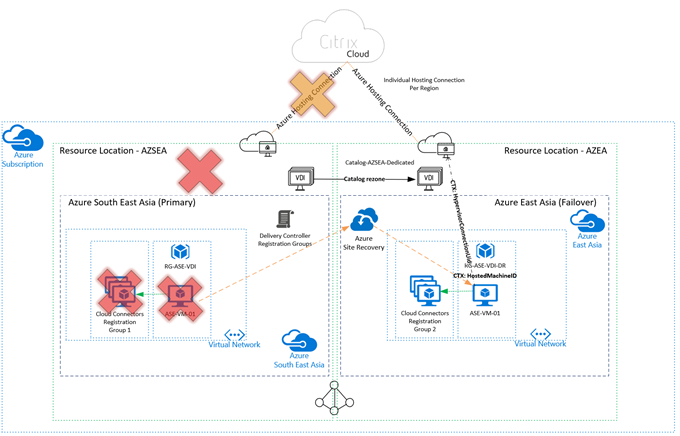
Single Azure Subscription, multiple hosting connections, one per Azure Region
Here is our second scenario in a fail state. Note that in this scenario, I needed to put the source (production) hosting connection into maintenance mode for sessions to launch.
Multiple Azure Subscriptions, multiple hosting connections, multiple regions
Note that I have not been able to test this scenario in earnest due to limitations in my Azure lab capability. However, the model should work, and ASR restoration across subscriptions is supported.
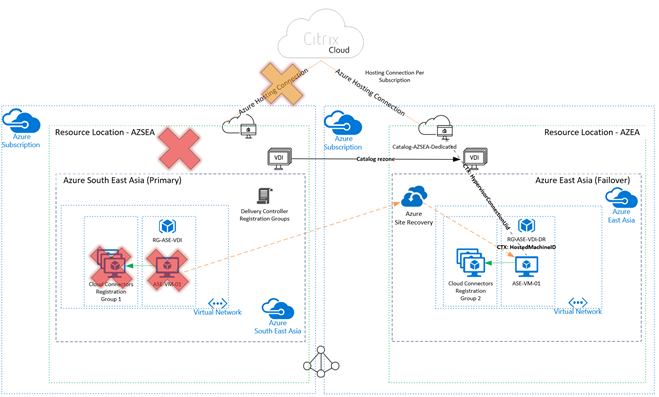
This is focusing purely on brokering services and there are additional considerations such as profile management, user personalization layers etc. that need to be considered outside of ASR capability.
Summary
I hope the above helps when working through capabilities associated with Azure Site Recovery and Citrix Cloud-based Dedicated VDI workloads. The good folks at Citrix (you know who you are) have been very helpful in sharing knowledge around how MCS operates and considerations of it in Microsoft Azure. They are also working hard to bring in additional availability options to ensure that we can leverage the power and availability options associated with Microsoft Azure.
