Architecting for FSLogix Containers High Availability

Desiging resilient solutions for FSLogix Containers
- Intro
- VHD Locations vs Cloud Cache
- Single SMB Location with single VHD Path
- Multiple SMB Locations with Single VHD Path and DFS
- Multiple SMB Locations with Multiple VHD Paths
- Multiple or Single Location Blob Storage (Cloud Cache)
- Multiple or single SMB Location (Cloud Cache)
- SMB Locations with Azure Considerations
- Replication Tools and Options
- Final Considerations
- Summary
Intro
FSLogix Profile Container is becoming the go-to solution when it comes to profile management. Even before the Microsoft acquisition, FSLogix was a popular solution, however now that it is effectively an entitlement for the majority of customers, its use will be greatly increased.
Implementing the solution is relatively easy. Dealing with high availability and navigating the options associated with containers, however, is not a simple task, and there are a few points to look at while deciding what architecture may be best suited from an HA perspective. FSLogix Profile Container and Office Container are simply redirecting a local profile into a VHD/VHDX, making it a block-level solution to profiles. These containers are mounted at user logon effectively mobilising a local profile. A mounted Container is effectively locked at the file system level resulting in challenges with consistent replication.
The following post will discuss scenarios relating to HA options and considerations around replication requirements.
VHD Locations vs Cloud Cache
There are two ways of defining profile locations in the FSLogix world. The first is the traditional path which allows writes to effectively any presented SMB share. Anytime the use of a VHDLocation is defined; we are automatically subscribing to a single active profile location methodology. Only one location can ever be active at one time.
FSLogix does not limit us to defining one location in the VHDLocation pathing; however, only one location based on the order defined, read, and detected as available will be active.
The second option is FSLogix Cloud Cache, an emerging capability which promises the holy grail of Active-Active profile locations.
This dream is realised with Cloud Cache by allowing us to define multiple profile storage locations, be it SMB or Azure Blob at the same time. Because both locations are active and there is a cache capturing reads and writes in the middle, seamless failover between locations can be achieved.
There are five common deployment scenarios I am going to outline below, along with the pros, cons, and considerations associated with each of them, as well as some tooling that can fill in the gaps.
Single SMB Location with single VHD Path
Depicted below is the most common and most simple deployment of the FSLogix solution. It leverages a single SMB location, (be it a Windows File Server, Scale-Out File Server, NAS presented storage such as Nutanix Files or NetApp option)s and requires simply defining one profile share location.
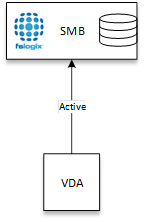
This model is simple to implement; however, in terms of HA, offers a single point of failure for container access.
Additionally, any backup solution that does not do block-level backup can struggle to backup the open container once it is mounted and locked.
Typically environments using this model of access rely on a storage level backup and replication solution alongside a manual restore process.
Multiple SMB Locations with Single VHD Path and DFS
The next scenario is the next most common deployment I have seen, and this is simply implementing what we have traditionally done with other profile solutions to achieve active/passive access. Simply placing a Distributed File System Namespace in front of one or many SMB locations.
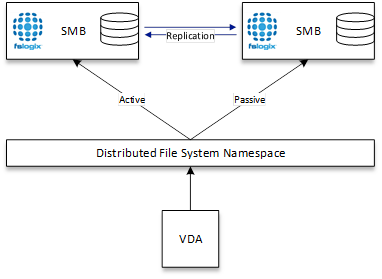
In this model, the same rules apply as far as a single VHDLocation is defined. However, the DFS namespace controls where that data lands and in which order.
DFS-N should always be configured in an Active-Passive methodology, ensuring that referrals and folder targets are appropriately leveraged, ensuring consistency of access and in typical useage scenarios, a supported architecture.
This model also introduces a requirement for something to handle the replication of containers across both locations in a consistent fashion (more on this later).
Multiple SMB Locations with Multiple VHD Paths
Choosing to use VHDLocations rather than Cloud Cache does not mean that the ability to define multiple locations is lost.
FSLogix allows for multiple paths to be defined to allow for failover should one location be unavailable. The priority for which location will be used first is defined by the order that the paths are specified in the VHDLocations path.
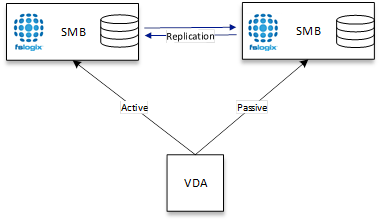
It is important to note that this model does not provide seamless failover and is designed to help cover the complete loss of a single storage location. There is no seamless failover when defining VHDLocations and as such, a reboot or more likely a reset of the users’ session will be required if a VHDLocation loss occurs in an unplanned fashion.
This model is particularly relevant for Azure-based deployments using VHDLocation with Azure Files, as there is no current way to leverage an Azure Files based file share as a DFS-N endpoint.
As with any multi VHD location-based architecture, there is a requirement to replicate the containers.
FSLogix doesn’t change the game when using VHDLocations regarding Active-Active architectures for solutions such as Citrix Virtual Apps and Desktops, and the same rules apply that would to any profile solution, the key here is architecting around this limitation in a supported fashion – probably a dedicated write up by itself at some point.
Multiple or Single Location Blob Storage (Cloud Cache)
Cloud Cache allows for the consumption of Azure Blobs via Azure Storage Accounts. One or many (up to 4) blobs across multiple Storage Accounts, allowing for true cloud-based storage consumption to be achieved.
Storage as a Service is what the “Cloud” in Cloud Cache is referring to. The rest of the engine is all about the cache.
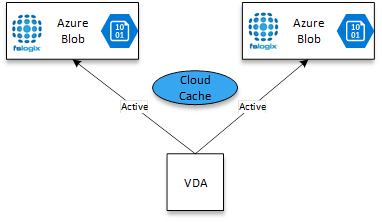
Blob storage was the first available option for Azure native storage consumption when leveraging FSLogix Cloud Cache, allowing for an individual blob to be created per user in an Azure Storage Account.
The benefit of this model, (along with the next) is that Cloud Cache removes the requirement for a replication tool to be in place and handles active-active profile locations natively. Cloud Cache also allows for the seamless failover between multiple locations.
There is a cost to this capability, and that is an impact on Logon and Logoff times for users due to the requirement to build a local cache on the endpoint. The impact will vary and you should test this against your deployment. Leveraging Service Endpoints on Azure vNets for Storage should help to reduce the impact.
Multiple or single SMB Location (Cloud Cache)
Cloud Cache is not limited to Blob Storage in Azure. It can be leveraged both On-Premises and with any Cloud platform that provides an SMB location to write data.
Cloud Cache can be utilised with any technology that VHDLocations can work with, allowing for active-active profiles across both on-premises and cloud-based locations.
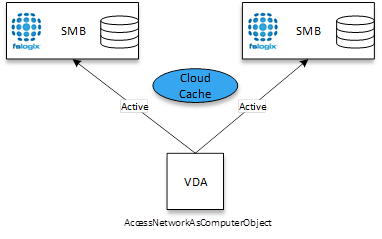
The keen eye may note above that the diagram specifies an AccessNetworkAsComputerObject tag. The reason for this is Azure Files specific and detailed in the next section.
SMB Locations with Azure Considerations
When consuming containers with Azure files via either Cloud Cache or VHD locations. There are a couple of key concepts to be aware of:
- To consume and utilise traditional NTFS style Access Control Lists (ACLs) you will require Azure Active Directory Domain Services. Azure Active Directory Domain Services is similar to traditional Active Directory Domain Services offered as a Service in Azure and consumable only by Azure-based virtual machines
- To bypass the requirement of ADDS above, FSLogix can be configured to access the Network Location for storing containers as the computer object. This combined with a neat trick from James Rankin where he outlines mapping a network drive in the computer context at machine startup allows for FSLogix to access these storage locations without Azure ADDS
- Azure Service Endpoints should help provide faster access to Azure Storage, as well as enabling a higher level of security and protection when used in conjunction with the access controls on the Storage Account
Replication Tools and Options
As discussed in the deployment scenarios above, whenever VHD Locations are utilised, and there are multiple paths at play, some for of Replication Software is required to keep these locations in sync. There are native tools, and there are 3rd party tools that I have utilised in different scenarios, a couple of free options are noted below:
Distributed File System Replications (DFS-R)
DFS-R is inbuilt to the Distributed File System technology within Windows and offers a decent level of replication capability for keeping two locations in sync.
It is a file-based replication solution meaning that it suffers from the same challenges that all file-based replication engines do, and has a nasty history across many deployments. I have seen this work with success; however, it wouldn’t be my first go-to solution these days. It is also important to note that should you be utilising REFS file system for your containers (which you definitely should where possible), then DFS-R will not be an option for you
Robocopy
The mighty robocopy is still a beast to this day and offers a fantastic free option for keeping your container data in sync. It is, however, once again, a file-based solution so will not be able to replicate mounted containers or locked files. This has been traditionally my preferred method of replication particularly when REFS is at play
BVCKUP2
I recently stumbled upon this little gem of a solution: BVCKUP2 developed by Alex Pankratov. This solution is unreal for enhancing and filling the shortcomings of Robocopy with an extremely thorough and well-designed user interface. The best part of this solution is that it can handle block-level replication meaning that replicating mounted containers is no issue. I have tested this thoroughly, and the tool is sensational as far as consistently replicating mounted containers in a fast and flexible fashion. I highly recommend this toolset for anyone looking to do multi-location replication of containers.


Yes it has a GUI, but it can also run as a Windows Service. The logging is sensational and I am struggling to fault the tool so far. I am going to be doing some in-depth testing with REFS and Azure Files based replication and see how it plays. I will post findings at a later date.
Final Considerations
A few final things to consider when you are designing your container solutions concerning all the scenarios discussed above:
Cloud Cache
Where it shines:
- You require a seamless failover should the loss of a single storage location occur
- You have active-active site requirements and prefer to keep containers close to workloads
- You want to consume native cloud storage such as Azure Blob
- You have latency struggles or concerns between the location of storage and location of workloads
Where it struggles:
- There are obvious logon and logoff delays which impact the user experience. This delay is variable based on many factors such as the location of the container in relation to the location of workloads
- It is a junior solution with a history of pain but a promise of great things
- Impact on PVS and MCS IO capabilities may be considerable
VHD Locations
Where they shine:
- You know what you are getting and how it works
- Far less impact on write caches such as PVS and MCS IO capabilities
Where they struggle:
- Manual replication requirements and an active-passive methodology only
- Lack of seamless failover
- Can only consume SMB locations. But this is becoming less an issue as Azure Files matures
Summary
As with any developing solution, these options will change, mature and differ over time. Furthermore, your mileage on the above may vary depending on your specific use cases and requirements.
Until next time…
